
Welcome to my personal webpage :)
My name is Banafsheh Karimian
My name is Banafsheh Karimian
You can find information about my academic background, research and projects in this website. For a summary, I have received my Computer Engineering bachelors from Iran University of Science and Technology and My Machine Intelligence and Robotics master's University of Tehran. Currently I am a PhD student at ETS montreal working on Knowledge Distillation.
In addition, as you can read in my research and projects , I have done research and projects in a wide range of fields in order to discover my interests. As a result, I found myself more interested in the following fields and tried to extend my knowledge in these fields. I would love to do research related to these fields, as much as possible.
GPA: 4.15/4.30
GPA: 19.02/20.00 - 4.00/4.00
GPA: 17.67/20.00 - 3.89/4.00
Casting complex inputs into tractable representations is a critical step across various fields. Diverse embedding models emerge from differences in architectures, loss functions, input modalities and datasets, each capturing unique aspects of the input. Multi-teacher distillation leverages this diversity to enrich representations but often remains tailored to specific tasks. We introduce a task-agnostic framework based on a ``majority vote" objective function. We demonstrate that this function is bounded by the mutual information between the student and the teachers' embeddings, leading to a task-agnostic distillation loss that eliminates dependence on task-specific labels or prior knowledge. Comprehensive evaluations across text, vision models, and molecular modeling show that our method effectively leverages teacher diversity, resulting in representations enabling better performance for a wide range of downstream tasks such as classification, clustering, or regression. Additionally, we train and release state-of-the-art embedding models, enhancing downstream performance in various modalities.
LinkMultimodal learning has shown promise in medical imaging, combining complementary modalities like images and text. Vision-language models (VLMs) capture rich diagnostic cues but often require large paired datasets and prompt- or text-based inference, limiting their practicality due to annotation cost, privacy, and compute demands. Crucially, available free unpaired external text, like pathology reports, can still provide complementary diagnostic cues if semantically relevant content is retrievable per image. To address this, we introduce CLIP-IT, a novel framework that relies on rich unpaired text reports. Specifically, CLIP-IT uses a CLIP model pre-trained on histology image-text pairs from a separate dataset to retrieve the most relevant unpaired textual report for each image in the downstream unimodal dataset. These reports, sourced from the same disease domain and tissue type, form pseudo-pairs that reflect shared clinical semantics rather than exact alignment. Knowledge from these texts is distilled into the vision model during training, while LoRA-based adaptation mitigates the semantic gap between unaligned modalities. At inference, only the vision model is used, keeping overhead low while still benefiting from multimodal training without requiring paired data in the downstream dataset. Experiments on histology image datasets confirm that CLIP-IT consistently improves classification accuracy over both unimodal and multimodal CLIP-based baselines in most cases, without the burden of per-dataset paired annotation or inference-time complexity.
LinkReinforcement Learning (RL) is mainly inspired by studies on animal and human learning. However, RL methods suffer higher regret in comparison to natural learners in real-world tasks. This is partly due to the lack of social learning in RL agents. We propose a social learning method for improving the performance of RL agents for the multi-armed bandit setting. The social agent observes other agents’ decisions, while their rewards are private. The agent uses a preference-based method, similar to the policy gradient learning method, to fnd if there are any agents in the heterogeneous society worth learning from their policies to improve its performance. The heterogeneity is the result of diversity in learning algorithms, utility functions, and expertise. We compare our method with the state-ofthe-art studies and demonstrate that it results in higher performance in most scenarios. We also show that performance improvement increases with the problem complexity and is inversely correlated with the population of unrelated agents.
LinkClassifier combination through ensemble systems is one of the most effective approaches to improve the accuracy of classification systems. Ensemble systems are generally used to combine classifiers; However, selecting the best combination of individual classifiers is a challenging task. In this paper, we propose an efficient assembling method that employs both meta-learning and a genetic algorithm for the selection of the best classifiers. Our method is called MEGA, standing for using MEta-learning and a Genetic Algorithm for algorithm recommendation. MEGA has three main components: Training, Model Interpretation and Testing. The Training component extracts meta-features of each training dataset and uses a genetic algorithm to discover the best classifier combination. The Model Interpretation component interprets the relationships between meta-features and classifiers using a priori and multi-label decision tree algorithms. Finally, the Testing component uses a weighted k-nearest-neighbors algorithm to predict the best combination of classifiers for unseen datasets. We present extensive experimental results that demonstrate the performance of MEGA. MEGA achieves superior results in a comparison of three other methods and, most importantly, is able to find novel interpretable rules that can be used to select the best combination of classifiers for an unseen dataset.
Link
Reinforcement Learning, although has plenty of advantages, is time-consuming and sample inefficient in many problems. Learning from Demonstrations, is used to improve Reinforcement Learning in many applications, such as robot learning and self driving cars. However, in most of the literature, it is assumed that the provided demonstrations are optimal, sub optimal, or at least, are performing what our agent wants to do. This is time consuming and costly to obtain in many tasks and requires human effort. In this work, we are going to use a heterogeneous set of demonstrations that are not directly related to our agent's goal, as behavioural policies, in the mentioned applications. To do so, we add a new term to the policy loss off SAC method. We assume that each demonstrator's policy is a point in the policy space that can guide us to improve our learning, similar to the figure on the left, and we will choose a behaviour policy to bias our decisions towards it. We use the idea of Free Energy frame work, and evaluate different methods of finding a behavioural policy that decreases the cost of policy search. We show that assuming the demonstrator with maximum evaluated return, evaluated using off policy evaluation methods, reduces the search cost considerably. View More

This research is about speeding the multi arm bandit and MDP problems with observations of other relevant or irrelevant agents. We propose a social learning method for improving the performance of RL agents for the multi-armed bandit setting. The social agent observes other agents’ decisions, while their rewards are private. The agent uses a preference-based method, similar to the policy gradient learning method, to fnd if there are any agents in the heterogeneous society worth learning from their policies to improve its performance. The heterogeneity is the result of diversity in learning algorithms, utility functions, and expertise. We then extend this method to MDP problem, generalize enough to address discrete and continous action and states.
View More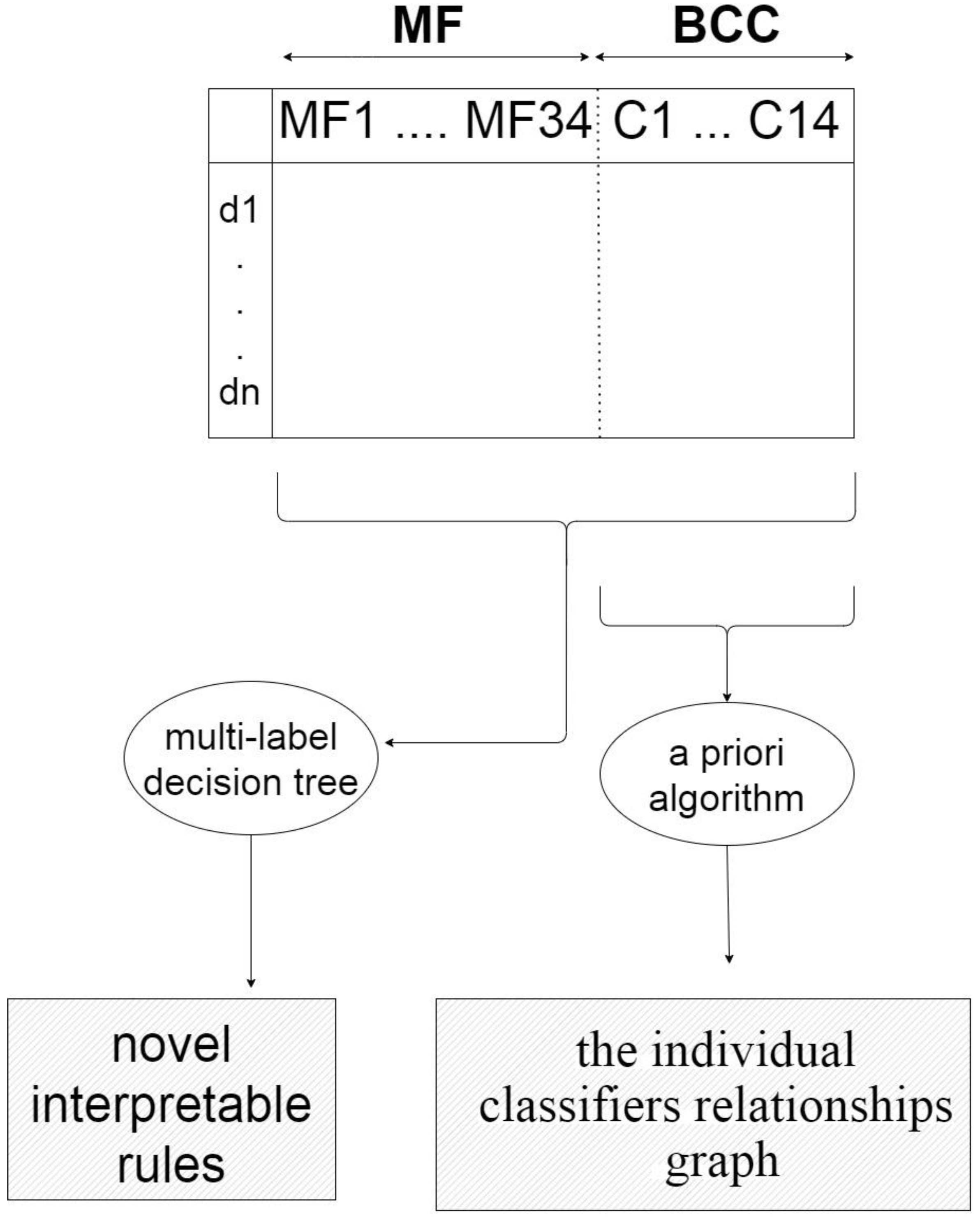
One of the most effective approaches to improve the accuracy of classification systems is using ensemble methods. However, selecting the best combination of individual classifiers is a challenging task. To address this issue we proposed our system MEGA, standing for using MEta-learning and a Genetic Algorithm for algorithm recommendation. MEGA has three main components: Training, Model Interpretation and Testing. The Training component extracts meta-features of each training dataset and uses a genetic algorithm to discover the best classifier combination. The Model Interpretation component interprets the relationships between meta-features and classifiers using a priori and multi-label decision tree algorithms. Finally, the Testing component uses a weighted k-nearest-neighbors algorithm to predict the best combination of classifiers for unseen datasets. For more information you can read our paper MEGA: Predicting the best classifier combination using meta-learning and a genetic algorithm. Intell. Data Anal. 25, 6 (2021), 1547–1563. https://doi.org/10.3233/IDA-205494.

Customized PyBullet Environment
An Environment with Franka Panda arm as the robot and multiple Goals for the agent to reach created using PyBullet. Demonstration videos are available at the .ipynb file.

Multi-Agent Deep Reinforcement Learning for Fighting Forest Fires
Implementation of multi agent reinforcement learning for forest fire retardant

Robot Localization
In this project, we used Particle Filter algorithm to localize our Vector robot both in simulation and real world maze.
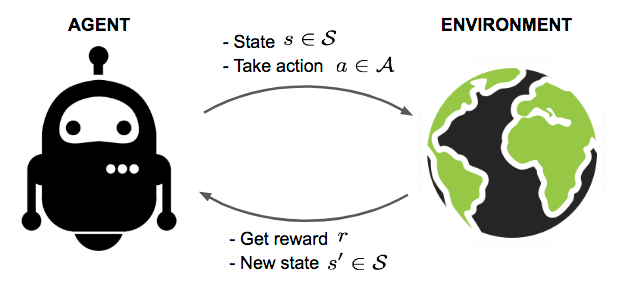
Reinforcement Learning Algorithms
Implementation of some reinforcement learning algorithms
Gossip Training Behavioural cloning for Self Driving Cars
We used gossip training in behavioral cloning for autonomous driving car.

TurtleSim Face Tracker
In this project we want to make the turtle in turtlesim move as our face moves and control it with our face.

Multi Agent Path Planning using Reinforcement Learning
In this project, we implement path planning algorithm for multi-agent system using Reinforcement Learning methods.

tBERT
In this project we implement TBERT: Topic models and BERT joining forces for semantic similarity detectio. Semantic similarity detection problem has applications ranging from question answering to plagiarism detection.
Read More
Cognitive Neuroscience Course Projects
In this post the projects that I have done for the cognitive neuroscience course are presented.
Read More


Thompson sampling
The thompson sampling algorithm is implemented for a 10 armed bandit with rewards similar to sutton barto's figure 2.1.


UTK Face age prediction
A Multi-layer Neural Network from scratch to predict age of UTKFace Data.
Transformer for Machine Translator
We implement the Decoder part of the Transformer from scratch.
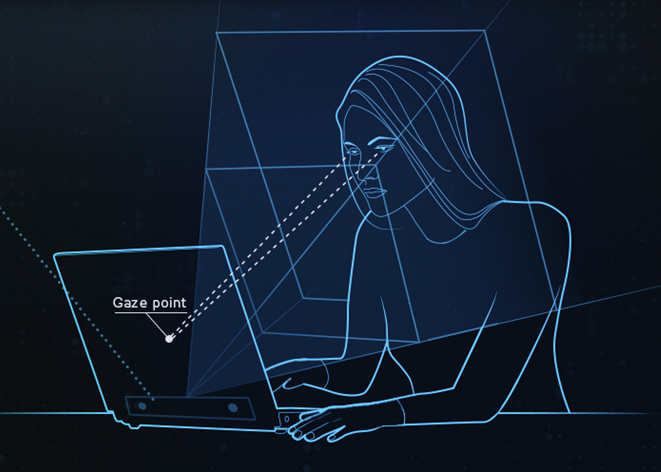
Eye gaze keyboard
We evaluated different approaches for detecting which key of the screen keyboard does the user looks at.
Read More

Stereo camera calibration
We implemented and improved an application for stereo camera calibration.

Detection of heart disease using UCI data set
Aim of this project was to apply multiple hierarchical classification algorithms on UCI heart disease dataset to achieve a good performance. The first layer of the classifiers separate only healthy from unhealthy individuals, and the second layer classifier predicts the heart problem of the individuals labeled as unhealthy by the first layer classifier. NeuralNetwork, Regression, DecisionTree and other algorithms were applied and the full results are shown in the following link.

Sentiment Analysis
After collecting the required data (positive and negative comments on products), the POS tags were calculated using openNLP toolkit. At the end the polarity was calculated for predicting the class label of each comment.
